TODO: full write-up…. For a standalone, full script written in bash for both accessing the twitter API and wrangling the initial raw dataset, please view: GitHub Script… For script functionality as a component of a full NLP project (which diagram is most relevant to), please view: GitHub Script
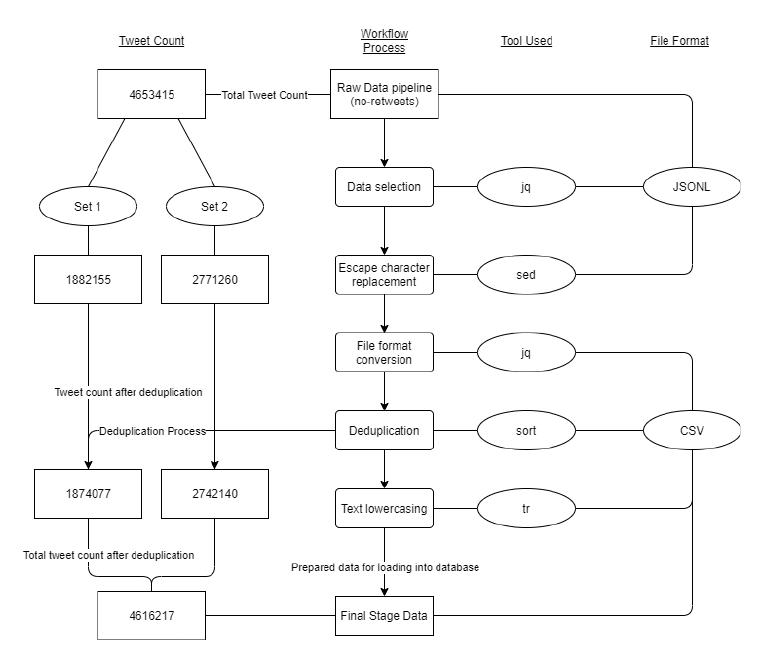
A diagram depicting bash script processes - the initial transformation workflow used on the gathered raw datasets: tweet property parametrization; character pattern matching replacing newline escape characters; format conversions from JSONL to CSV; removal of duplicate tweet entries; and text lowercasing. De-duplication removed an extensive 37000 unwanted data records.
Return Home

