I put together a webscraping application that scrapes and retrieves data based on an automatically generated URL from user-provided filters that delimit data from a complex, variegated, and vast web source. By including filtering functionality at the level of data sourcing reduces the amount of time and resources that would be spent on required data wrangling later. However, the query parameters that altogether compose the targeted URL must fit the conventions that form the internal data query of the origin website and specific page-of-search as URL architecture is very sensitive to any deviation – and to internet protocol.
I chose this method of webscraping to use on a property listings website, in particular sales listings, because of the wide variety of property listings that are categorized by their different features; which are only of interest to the user by each of their individual categorizations - not all at once. For instance, even if you can webscrape a particular region, you may not want your entire dataset littered with 5-bed new build properties when you are only interested in sold 2 to 4-bed properties with parking. Therefore, from a data source, such as: a property listings website, the very features you might want to shape your dataset with can include a wide variety of logical parameterizations.
Although aspects most related to the process of generating target URL objects is the focus of this writing, I have still briefly outlined the build and workflow for the webscraping tool in the next diagram.

The application begins at user input, which is primarily via a command line interface, however, the tool can still be loaded as a library. This is an example of what a command to initiate and scrape data could be like:
propertylistings --save-file search --pages 30 --region devon --max-beds 6 --min-beds 4 --max-price 650000 --new-home, --no-retirement --offer-sold
A more in-depth overview of what each of the options entail and guidance on usage can be found here in the docs on my GitHub or on pypi. Proceeding the user command, the filters provided instantiate the build of the query parameters that will guide the structure of the URL object. The URL object is first compiled in the URL generator before it is provided, as a returned string object, to form part of the entire URL that includes the website domain name. The created object is then used as a target for the webscraper tool. In addition, as one of the filter parameters provided in the user command refers to ‘pages’, the webscraper is able to scale and not be limited by a target of only a single web front for webscraping. The very webscraped data can be returned as either a comma separated value file, or as standard output, which makes the overall application also great for workflows.
To begin the parameterization of user filter inputs into a cohesive URL, qualitative definition of the generated URL must fit the expected conventions of what the website typically uses for webpage data retrieval. Which refers to the very composition that interconnects each of the query parameters that respond to different categoric search parameters and filters from the perspective of the target website, as well as, URL type convention – which we will not go into full detail right here and now. The main logical conditionality that underpins the structural elements of the search parameters for this website was primarily of a boolean characteristic, however, there are also cardinal parameters that could be included in the search query, such as: house values or number of bedrooms. A simple example of what this boolean characteristic could look like, was with the offer sold parameter – referring to properties that are either under offer or already sold – which is default as false (naturally not present at all in the URL) in the target website. However, by providing the offer sold parameter in your command will integrate the offer sold value and result in its inclusion within the generated URL object string, as: “&includeSSTC=true”, the “&” is a critical component for stringing search query parameters together.
A more interesting and complex boolean characteristic where more logical conditionality was directed and techniques for building the URL objects performed, was with the principles of must have and do not show features. First of all, the must have features were split into two separate functions: set 1 (garden, parking, and auction); and then set 2 (retirement, shared ownership, and new build). This was done for two main reasons, to condense the method of generating URL objects – which will be described in more detail in a moment – and because set 2 were features that were also present in the do not show parameters, by isolating them allowed for clear troubleshooting and diagnostic methods.
The main challenge, with regards to both formulating and integrating URL parameters from user input into a full URL query, was how it matched the conventions of the URL typing for the target website. This challenge was further complicated because the generating of URL feature parameters had to scale based on user input, where such filters were under the same filter parameter category, and again meet the conditions of requirement that fit the search parameters of the targets website URL. Firstly – specific to ‘must have’ parameters, the conditionality for both ‘do not show’ and ‘must have’ parameterization were similar – the generating of URL parameters that included multiples of the same search parameter categories did not work, they must be provided as a linked-stream of input search parameters. For example, URL object “&mustHave=garden&mustHave=sharedOwnership” will not retrieve the expected data, the search could work in terms of loading, however, using both conditionals in that form would not be recognised in the search, so only one search parameter would be used to filter the dataset, or none at all. So, for that example to work, it must be integrated into the URL in the form of: “&mustHave=garden%2CsharedOwnership”, with “%2C” as the conjunctive character – which I believe is recognised across all Internet browsers. Therefore, as the must have feature category, relevant to this target website, was made up of six features, the generated search parameter had to scale up to the greatest potential of user inputs, which could be something akin to:
"&mustHave=garden%2Cparking%2CnewHome%2Cretirement%2CsharedOwnership%2Cauction"
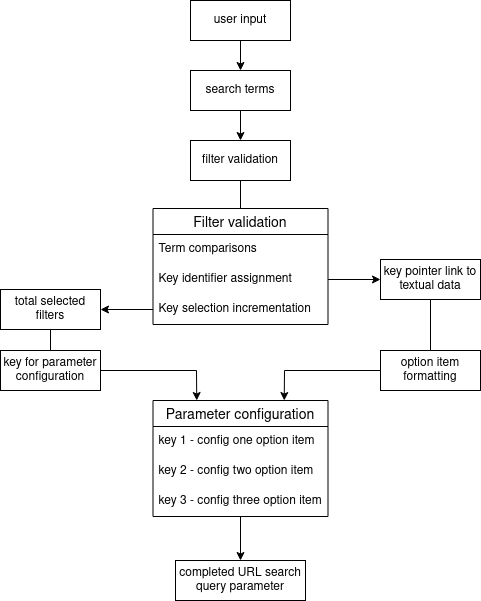
So, by using dictionary data structures and objects to hold integrate values that form part of the URL in-line with boolean point conditionals that met user input filters, I was able to generate valid search query parameters based on user input – which can be seen in this module here on my GitHub. The data structures consist of three point string parameters that can be formatted – a limit of three points were selected only to maintain the size of the logic (they can be combined to form more, view function: must_have_URI) – which can be viewed as: “{option_1}%2C{option_2}%2C{option_3}”, and the paired key identifier would be 3, also matching the amount of provided feature parameter filters. On the other hand, if only 2 parameter filters were required in the user input, it would instead match up to: “{option_1}%2C{option_2}”. This very point parameter, regarding option values, can be formatted based on the provided filter inputs, and the number value relevant to the key identifier represents the counted request filters supplied in the user input. An incremental method is applied to how selection of filter pairs to their according option format in the intended URL object. For instance, within the must have function of the URL generator class, if in a request had true the search for house properties with parking and garden was made, the key identifier would eventually be 2 out of 3 (as auction property is false); when the first filter is read as true in the made conditions, the key identifier is incremented to 1 and that also becomes the selection pointer to the relevant textual data, such as: garden, so when the next true filter is read, such as: parking, the request key identifier is incremented to 2 and so is the selection pointer for that filter option. Therefore, the relevant final key identifier result corresponds to its point parameter, such as: “{option_1}%2C{option_2}” for 2 filters read, and in terms of formatting the string, correspondence is with the sorted selection of textual data that is paired with its appointed selection number based on its incremental status, in this case: 1 for garden; 2 for parking, which altogether formats to “{garden}%2C{parking}”. An overview workflow diagram depicting the search term filter validation and search query parameter configuration can be seen below:
For more information regarding the webscraper CLI tool, code and usage guide, can be found here
Return Home

